到中科院以后集中学习大模型底层技术。承接了一些国产GPU算子优化的科研项目。本质上,就是把DeepSeek团队在N卡算子上做的惨无人道的底层优化在国产卡上再做一次。
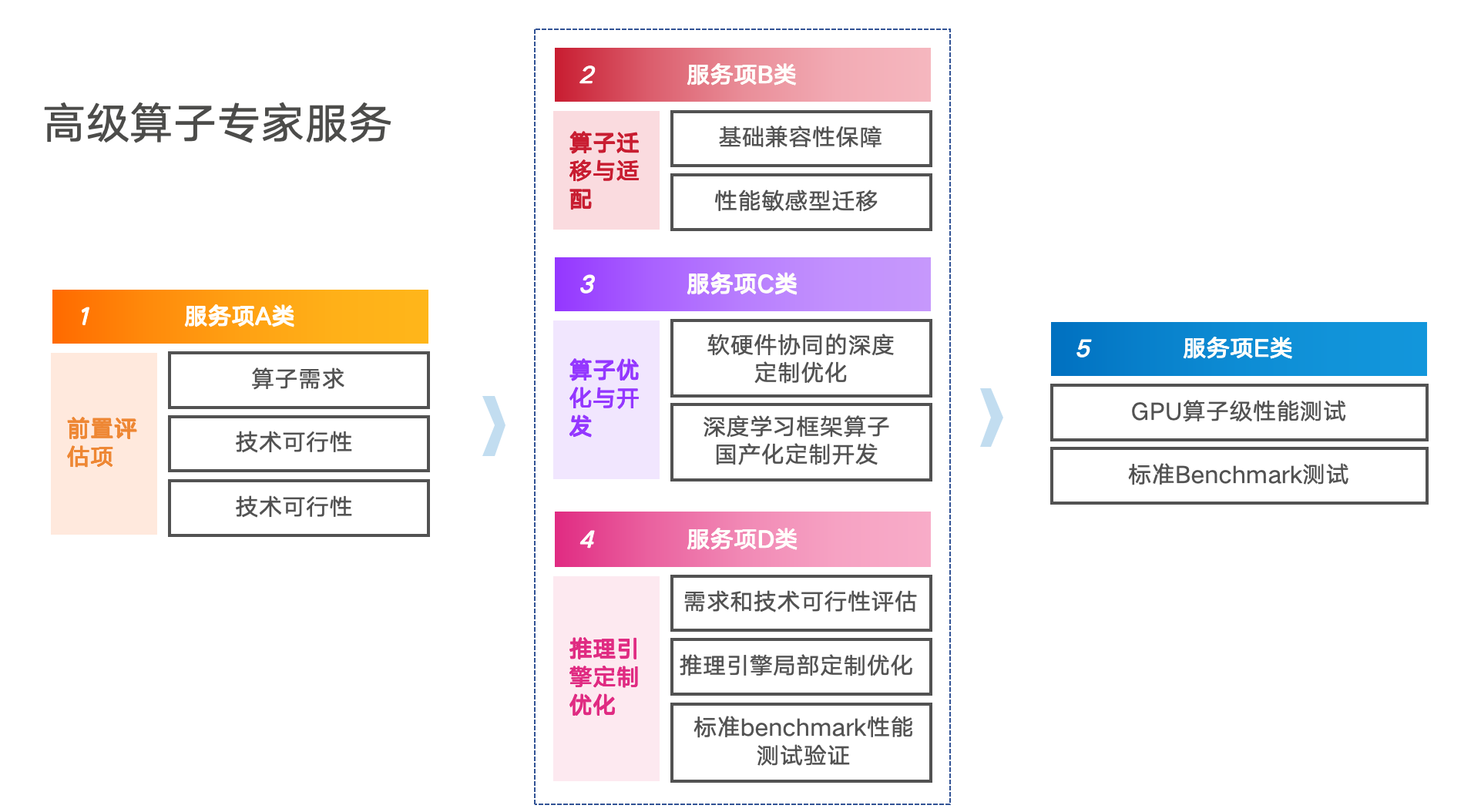
团队对外提供成套的高级算子专家服务,坦率说不便宜,有需要的找我。
GPU是众核并行计算设备,通过线程块与网格组织计算。常规算子优化分为四层:
汇编层面:直接操作指令集,调整寄存器分配、指令调度,隐藏延迟。技术包括寄存器分块、指令重排、消除Bank冲突等。
C++/高层语言内核优化:使用CUDA C++/HIP编写,优化内存访问模式(如数据布局NHWC/NCHW)、向量化加载、共享内存使用。
中间表示(IR)层自动优化:TVM、MLIR、Triton等框架将计算与硬件解耦,通过调度原语和自动搜索(AutoTVM/Ansor)寻找最优分块、循环展开等参数。
算法层面创新:如FlashAttention重排计算顺序,降低内存复杂度。
不同计算场景也有不同的技术特点:
大语言模型:预训练核心是GEMM(矩阵乘),需优化通信与计算协同;微调(如LoRA)需处理小矩阵乘的批处理与融合;推理需优化KV Cache管理(PagedAttention/RadixAttention)、动态shape与连续批处理。
多模态模型:需处理视觉(卷积、Patch Embedding)与文本(Transformer)算子的融合,支持跨模态注意力与动态shape。
视觉模型:CNN(规则访存)与ViT(类似LLM)的优化路径不同,需支持算子融合与量化。
传统深度学习:推荐系统需优化稀疏嵌入查表;图神经网络需优化稀疏矩阵乘(SpGEMM)的负载均衡。
算子优化主要采用以下各种优化技术:
分块(Tiling):将数据划分为适合缓存层次的块(全局→共享内存→寄存器),提升数据重用。
双缓冲:用两组缓冲区交替加载与计算,隐藏内存延迟。
Warp操作:利用warp内线程的快速数据交换(如__shfl_sync),减少共享内存访问。
向量化访存:使用float4/float8等向量加载,提升带宽利用率,要求内存对齐。
数据布局转换:如NCHW/NHWC布局选择,优化访问合并度。
持久化Kernel:长期运行的线程块处理任务队列,减少kernel启动开销。
相比N卡,国产GPU面临一些独特挑战:生态不成熟,硬件细节不透明,性能可移植性差,多卡互联方案(PCIe/CXL)带宽、延迟与NVIDIA NVLink有差距。而且需要优化算子数量还很多。一般会采用分层策略:核心算子(GEMM、FlashAttention、卷积、归一化)投入专家手工极致优化,而固定模式算子(Element-wise、Reduction)通过模板+参数搜索实现常规优化,对长尾/动态算子则通过编译框架自动生成。再激进一点,基于微调后的专用算子编程大模型进行自动探索优化。
对于极致优化,以GEMM算子为例,优化思路包括:
分块:全局→共享内存→寄存器多层分块,尺寸权衡占用率与寄存器压力。
指令级优化:围绕矩阵计算单元(如Tensor Core)定制指令。
双缓冲:异步加载下一数据块,隐藏访存延迟。
精度支持:适配FP32/FP16/BF16/FP8/INT8等,设计缩放与累加策略。
批量与形状:小batch时需合并计算;非常规形状(如LoRA的低秩乘)需单独设计。
对于模板+参数搜索自动优化,目前有3种技术路线:
TVM/MLIR:通过张量表达与调度原语描述计算,自动搜索优化参数。
TileLang:以tile为核心抽象,显式表达分块与数据布局,由编译器生成底层代码,平衡控制力与自动化。
Triton:限制编程模型自由度,编译器自动生成高效代码,适合快速补齐算子。
无论是哪种技术路线,适配国产GPU需后端映射硬件指令、构建性能模型指导搜索、并通过系统化测试验证。
我知道你们想了解除此以外的更激进更酷的第三种方法:基于微调后的专用算子编程大模型进行探索,甚至发明人类没发明过的新算法。这个路线和上面两种路线并不是冲突的,而是必然以上面两种工程经验和模板工具为基础,加上更多自主编程和迭代。具体细节不能讲太多。今年国外已经有论文,自己去搜吧。
最后,对于优化效果的评价可参考KernelBench的算子定义与评估思想,在国产GPU上重建参考实现作为基线。测试覆盖核心算子(GEMM、卷积等)的各种精度、形状与布局。通过相对性能加速比、带宽利用率、数值误差等指标综合评估。此外还应该增加常用大模型的E2E案例压测。
