1. 为什么选择基因数据作为创业的起点?
2014年,厦戎和我创立GeneDock(聚道科技),希望用数据技术改变临床诊疗,这个使命始终没变。
创立那年,中美两国允许基因测序技术进行临床试点,通俗点讲就是医生可以依据基因数据给人看病了(此前十几年,人类基因组计划等项目处于科研阶段,还没有成熟到可以应用于一线临床)。所以我们先从基因数据的处理下手。
2. 最初面临什么业务场景?开发了什么产品?
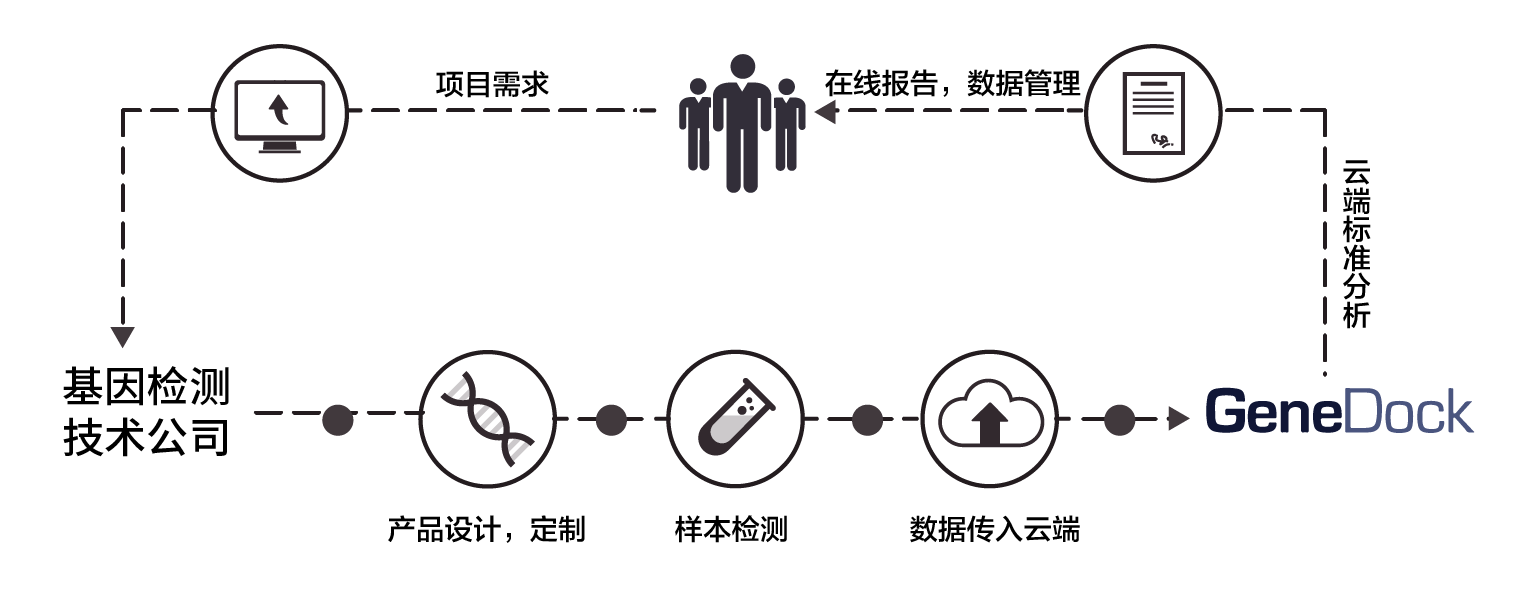
GeneDock最早的客户是基因检测技术公司和科研机构,典型的业务场景是这样的:每天,不同城市的测序实验室产生上T的基因数据,先进行生物信息处理,再把数据和报告交付给下游客户,交付周期有商业承诺。领导数据生产部门的CIO往往面临很多复杂问题:
- 首先,原始的测序下机数据无法直接应用,必须经复杂的拼接比对计算方能获得基因突变信息,而且还要对突变进行注释和解读。这就需要调度巨大的计算能力,管理庞杂的分析流程,维护复杂专业的参考数据库和样本信息。
- 进一步,需要进行细粒度的业务划分和配置:实验团队、生物信息团队和遗传咨询团队处于上下游的不同环节,不同角色应该给予不同权限;而不同的检测种类,也会导致分析步骤的巨大差异,需要专门的分析流程、报告模版配置和数据隔离。
- 同时,需要对各检测种类的不同处理步骤进行成本统计;对关键数据的使用和修改进行安全审计;对业务全局信息提供仪表板和显示大屏。
- 更复杂的情况下,客户经常把一部分数据生产工作外包,例如基因测序外包给大的测序工厂,或者遗传解读外包给专门的医疗信息团队,这就必须对跨组织的数据交付、数据质量进行管理,对安全进行审计,对业务进行定期结算。
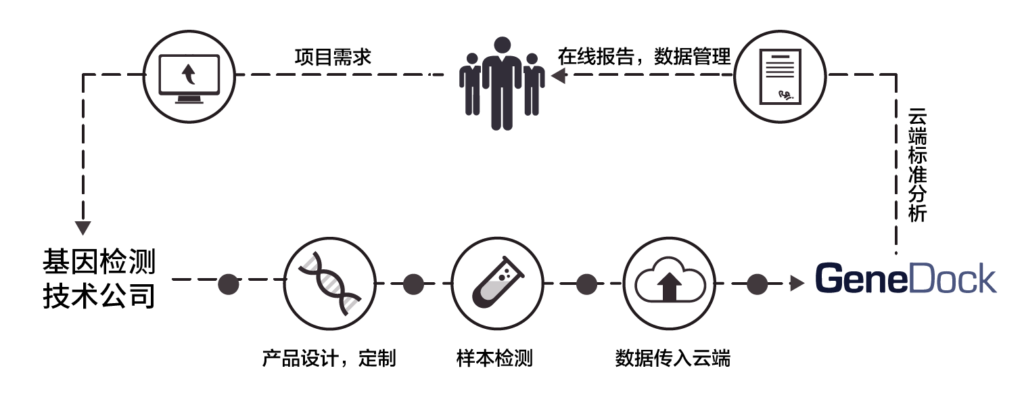
针对以上场景,从2014年开始研发名为SeqFlow的基因数据生产线。这个产品首先是支撑海量计算存储的数据平台,对稳定性、算法优化、高吞吐和弹性拓展能力的要求都很高,以保证客户业务的质量、交付周期和成本控制。在此基础上,SeqFlow还增加了企业级的管理大屏、项目管理、权限隔离和数据审计功能,以便管理者对基因数据业务进行高效管理。
3. 研发SeqFlow的关键点是什么?
SeqFlow的研发重点在于硬核技术,举个例子:分布式调度方面需要把计算任务表达为有向无环图(DAG),这个DAG是瘦长型的,步骤很多,最复杂的癌症肿瘤数据需要上百个步骤,很多步骤依赖成熟的算法包。这就导致常见Hadoop、Kubernetes等框架都无法满足需求(其实今天的Kubernetes是可以用的,但是4年前Kubernetes和其他几种类似框架都不完善,测试时发现了很多致命Bug)。所以我们就自己从头开发了一套分布式计算框架,刚好可以加上很多企业级服务的特性,例如冷数据压缩、项目隔离、Policy鉴权、管理大屏、数据审计机制等。
刚进入这个领域的时候,市场上30X的人全基因组数据的常规处理价格是800元。2016年的时候,GeneDock发布了全球第一个价格低于100元的人全基因组数据处理服务,同时,这个服务承诺很高的并行处理通量,以及低于万分之一的失败率。我们为整个行业的发展构建了工业级的高性价比、高吞吐量、高稳定性基础数据生产平台。目前,SeqFlow上生产的客户包括泛生子、艾吉泰康、微基因和华大基因等行业领头羊。
4. GeneDock为何向医院客户拓展?
基因测序技术刚开始临床试点时,大多数医院对它不熟悉,所以把业务外包给第三方检测公司。随着人才和数据的积累,顶级医院开始筹建自己的分子诊断中心:招聘团队,购买软硬件,建立实验室……要在院内完成整个基因检测的闭环。因此,他们也就逐步有了数据平台的需求。
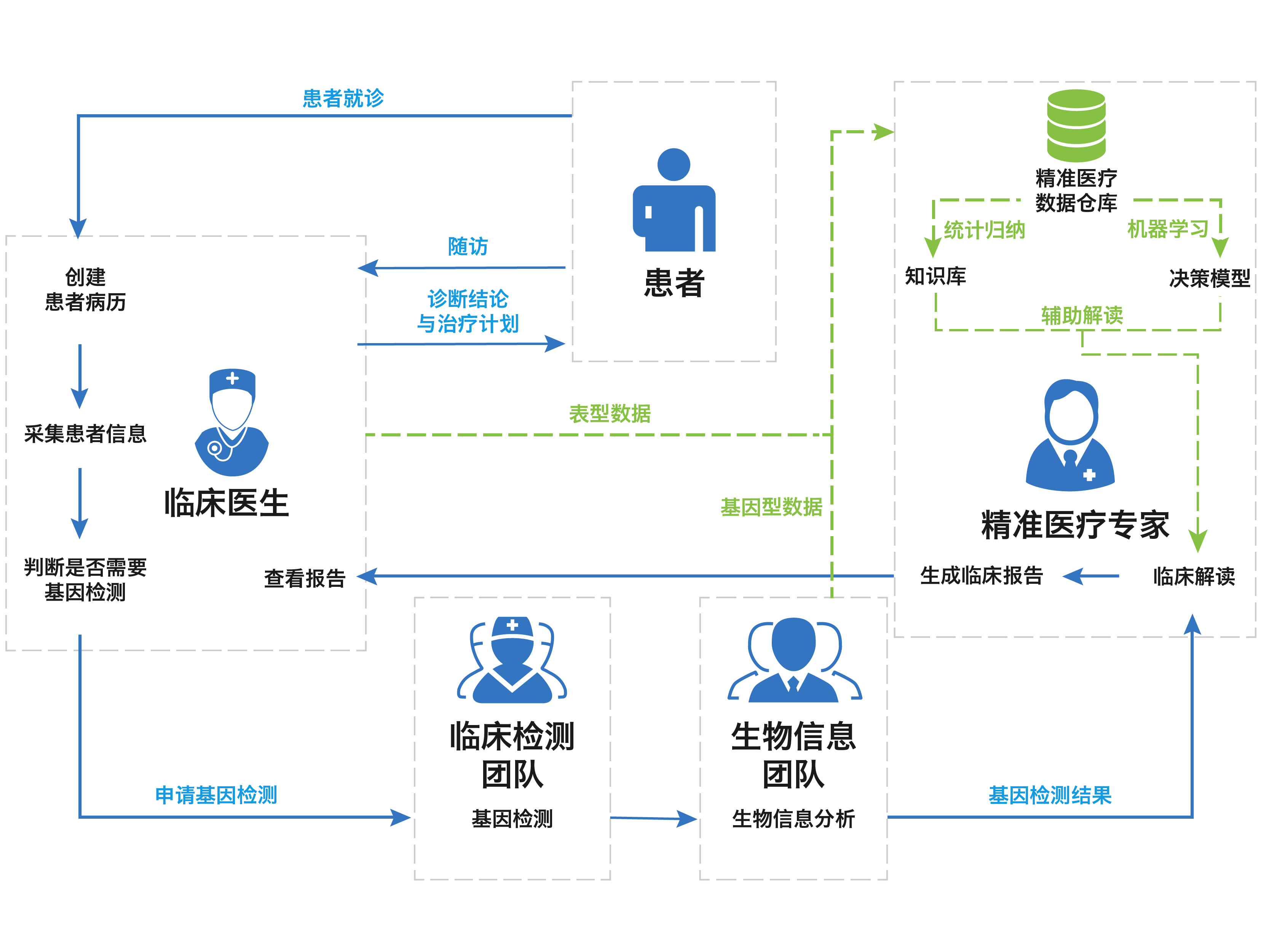
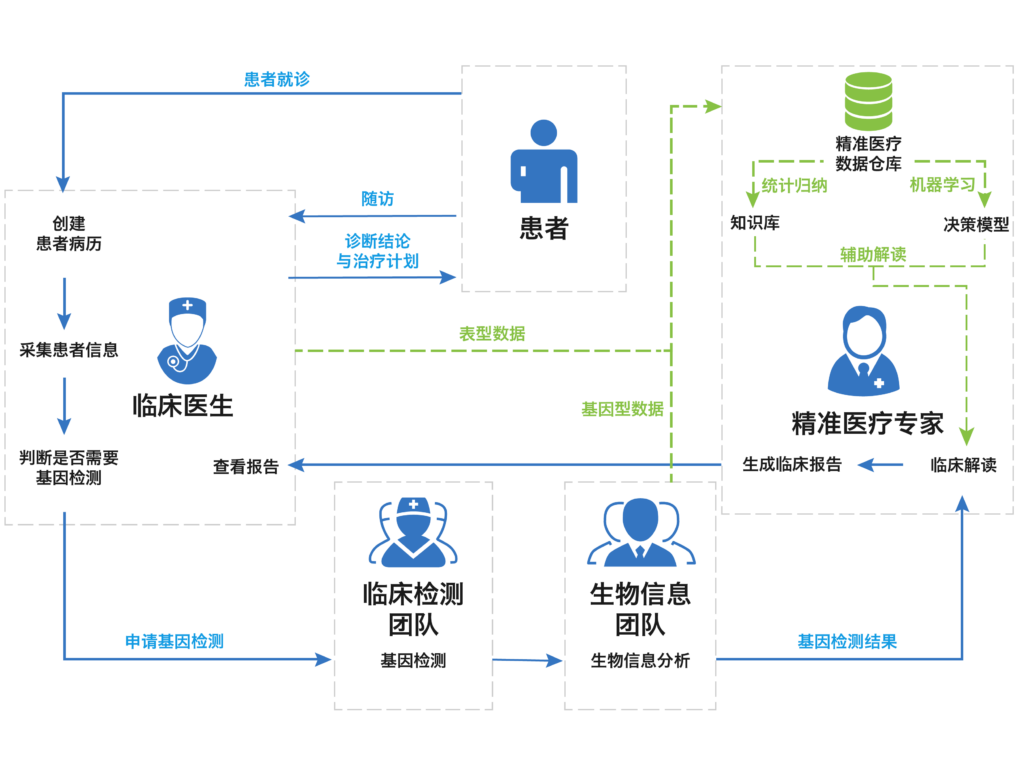
经过几年的探索,GeneDock从2016年开始全力开拓临床客户。和工业界的生物信息工程师不一样,医生不会写代码,这就要求我们从PaaS上到SaaS,把诊疗场景的产品做透。具体场景包括门诊电子病历收集、实验室管理、生物信息数据处理、位点和诊断报告系统,以及在此基础上构建的数据仓库和人工智能系统,最终实现临床辅助决策支持系统(CDSS)。
5. 基因数据与临床结合,面临哪些核心问题
临床诊疗是非常专业的领域,场景更加复杂。所以研发难度不仅限于技术实现,而在于能否拥有清晰的业务洞察,设计出专业而易用的产品。得益于早期客户的信任和帮助,团队有机会一次次跟随专家出诊和试验,逐渐理解遗传诊疗过程。举几个例子:
- GeneDock以前开发过科研病历,以为这套系统可以直接搬过来应用于一线门诊。后来才意识到不对。科研病历往往简化时间维度,把几百个字段平铺开,而门诊病历必须体现诊疗探索过程:根据症状,按指南检测,每一步检测带来更多信息,又决定了下一步的检测治疗方案。
- 门诊节奏非常紧张,有时医生甚至几个小时没法喝口水,临床数据系统必须提供友好的半自动化录入和专业的检索统计。
- 涉及基因数据的疾病,往往是遗传相关的。这就需要一套非常专业易用的家系图管理系统,通过家系信息把病历信息、实验样品信息、生物信息流程、检测报告、诊断信息都串联起来。
- 在实验环节,样品无论外送或自做,都需要精密的实验步骤管理和质量控制,各个医院操作规格不同,又需要自主配置,具体实验室环境下,实验员一旦进入无菌操作环节就必须一气呵成完成操作,这时候突然要求他摘下塑胶手套到电脑键盘敲入信息是不现实。这就需要对场景和交互进行细致理解和思考。
关于更具体的场景和技术方案,我在很多公开场合分享过。例如2018年初在顾大夫沙龙做的报告《面向临床的基因型和表型数据管理》。今天的公众号会转发那次活动的总结,其中包含了我的PPT。
6. GeneDock的系统已在哪些医院投入实用?
随着对临床诊疗的理解逐步深入,面向遗传疾病诊疗的数据系统逐步打磨完善,完整覆盖了从门诊病历、实验流程、生物信息分析直到生成诊断报告的完整诊疗流程。GeneDock的数据平台已经陆续在陆军军医大学第一附属医院、四川大学华西医院、上海新华医院、厦门大学附属中山医院、中国医学科学院肿瘤医院、中信湘雅生殖与遗传专科医院、江苏省苏北人民医院、首都医科大学宣武医院等多家客户处投入实用,还有更多顶级医院正在落地。
7. 目前AI是热点,GeneDock有什么成果?
在清洗好的海量基因数据和临床数据基础上,我们和临床科研专家一起合作,利用统计机器学习方法训练出了非常有效的人工智能算法模型,能够从成千上万遗传变异位点中,自动选取出最有可能导致疾病的遗传病因。
在2018年的美国人类遗传学会(ASHG)年会上,陆军军医大学第一附属医院(重庆西南医院)医学遗传中心与GeneDock合作开发的遗传性耳聋基因变异功能预测模型DVPred刚刚发布。这个模型明显提高了预测准确度,ROC曲线的曲线下面积(AUC)达到0.998,在遗传性基因变异功能预测方面表现出更高的准确性,灵敏度高、特异性强。
我们正在和客户继续研发,希望类似“大数据宝宝”的案例越来越多,让更多的患者真正受益于数据技术和人工智能技术。
8. 创业四年下来,你个人有什么总结?
反思当然很多了,有一些是关于沟通、招聘和管理的,不多说。
关于复杂系统的工程研发,这两天重新看了自己2015年梳理的博客《思考:如何开发应用平台》。感觉当时写得还不错,现在回头再看,很多观点都被验证了。当然,侃侃而谈是一回事,事到临头真处理好不掉进坑里,又是另外一回事了。有些东西必须躬身入局经历一番才算真懂。这一期公众号,这篇老文章也会发出来。
总而言之,能构建起一支专业的软件工程团队,很有成就感。
9. 完成了B轮融资,接下来重点是什么?
GeneDock会和越来越多的专家团队合作,对更多业务领域进行探索。不仅限于简单遗传模式的疾病,也开始涉及癌症、帕金森等复杂疾病,逐步覆盖生殖三级防控(婚前、孕前和产后)的各个阶段。
具体到眼前这个阶段,随着标杆客户案例的建立,已经很多公司和医院的业务开始落地。项目交付能力至关重要,这取决于整个团队的软件工程水准:从需求分析、产品设计、研发迭代、测试发布、部署上线……要有一整套成熟高效的工程体系。这方面是GeneDock团队的强项。当然,团队还需要补充很多人才。
10. 对于想加入GeneDock的人有什么建议?
随着B轮融资的到位,资金不再是问题,我们需要更多的程序员、基因数据工程师、人工智能专家和分子遗传学专家,对临床和基因数据进行充分的挖掘和建模。更详细的职位描述,欢迎访问 https://www.genedock.com/joinus/。
除了具体技能,个人想提醒的是,创业公司都会有一定的不确定因素。投简历之前一定要想清楚:心态上来说,创业变数多,需要有很强的抗压能力;能力上来说,需要你独当一面,有很强的落地执行力。GeneDock初步打开了局面,现在加入对个人而言有很广阔的成长空间。欢迎入伙!