关于DeepSeek(1):稍早前DeepSeek对我说:宇宙的沉默或是最大的警钟。文明或如萤火,短暂照亮黑暗便熄灭。人类若想跨越 filter,必须证明自己不仅是“会使用工具的猴子”,更是能驾驭技术之火的智慧生命。
关于DeepSeek(2):让DeepSeek比较当年钱学森的《工程控制论》和目前最新的自动驾驶技术的理论框架。它在解释“状态空间”这个概念还挺到位。
关于DeepSeek(3):问DeepSeek:“33550336是一个完全数,解释一下”。它的回答令人叹为观止。(后注:12月DeepSeek发布了 DeepSeek Math,原来如此)。伟大的DeepSeek赶紧发布R2吧。全中国的程序员都在苦等传说中的DeepSeek Code新版来拯救。现在中国程序员被美国大模型服务针对性折腾,太不爽了。
关于AI的商业化:奥特曼一本正经地回答过投资人,OpenAI 的计划是先造出通用智能,然后直接问它如何赚钱。另一方面,DeepSeek的母公司用AI炒股票已经可以做到每年上百亿美元收益,所以他们不太关心大模型如何商业化赚钱的问题。这比美国那边OpenAI承受的压力小多了。
关于Agent:在航空英文词汇里,Copilot是副驾驶,Captain是机长。回到计算机专业,造Agent的最终目标必然是造Captain而非Copilot。我去年因为这个和别人发生了剧烈争论。看不见、看不起、看不懂、追不上。大多数人都是这样。OpenAI 最新发布的那个 ChatGPT Pulse,不就是大模型版的今日头条嘛。字节跳动的同学们赶紧啊。这才是Agent该有的样子。Andrej Karpathy判断哪些工作会被 AI 替代的标准(或者说,可以用来考虑那些场景可以尝试开发Agent):不看工作的复杂度,看可验证性。单看IT领域,所有能实现自动化测试的场景,都会最终实现“人在环外”。所谓人机协同,大多数是伪命题。
关于Infra:重新去阅读很多infra的文章和博客,发现了这一句“知识是病毒,专家是载体,只要有好的交流方式,知识就会不断传播,就会有新的专家成长。”基础设施层的演进速度真的匪夷所思。上半年王坚院士把大模型塞进卫星里发射到太空就够抽象了,最近看到的很多东西吓到我了。
关于华为:华为把盘古大模型的部门彻底裁撤了。现在进入纸糊必死的时代,即使试图纸糊的品牌叫华为。另一方面,AI芯片方面,华为清晰的列出了接下来三年的产品roadmap,包含芯片型号、预计技术规格和产能,包括出现意外时的取舍优先级。这种产研迭代的节奏感让人肃然起敬。
关于Data cloud:研究了一下Snowflake近况。自己纸糊的大模型基本上停掉了。集中精力继续做Data Cloud基础设施。目前强调自己是业务-分析-推理三合一。业务就是OLTP,分析就是OLAP,推理是正在摸索的AI接入。股价创新高。
关于Anthropic:好诡异,Anthropic居然在老版本模型下架的时候,安排对模型(不是对模型的人类用户)进行访谈,收集模型自己对运维、部署和未来开发新模型的建议。这是完全把大模型当活人对待了吗?
关于传统互联网平台:Amazon 正式起诉 Perplexity AI,因为后者的Agent开始帮人类在Amazon商城上自动买东西,这摧毁了电商大数据推荐广告的技术根基。豆包手机助手一上线,就被微信在内的各种平台封杀,逻辑一样。平台自己的NLP界面做出来之前,不会接受任何其他AI挡在APP和用户之间。问题是,用户最终只需要一个Jarvis。
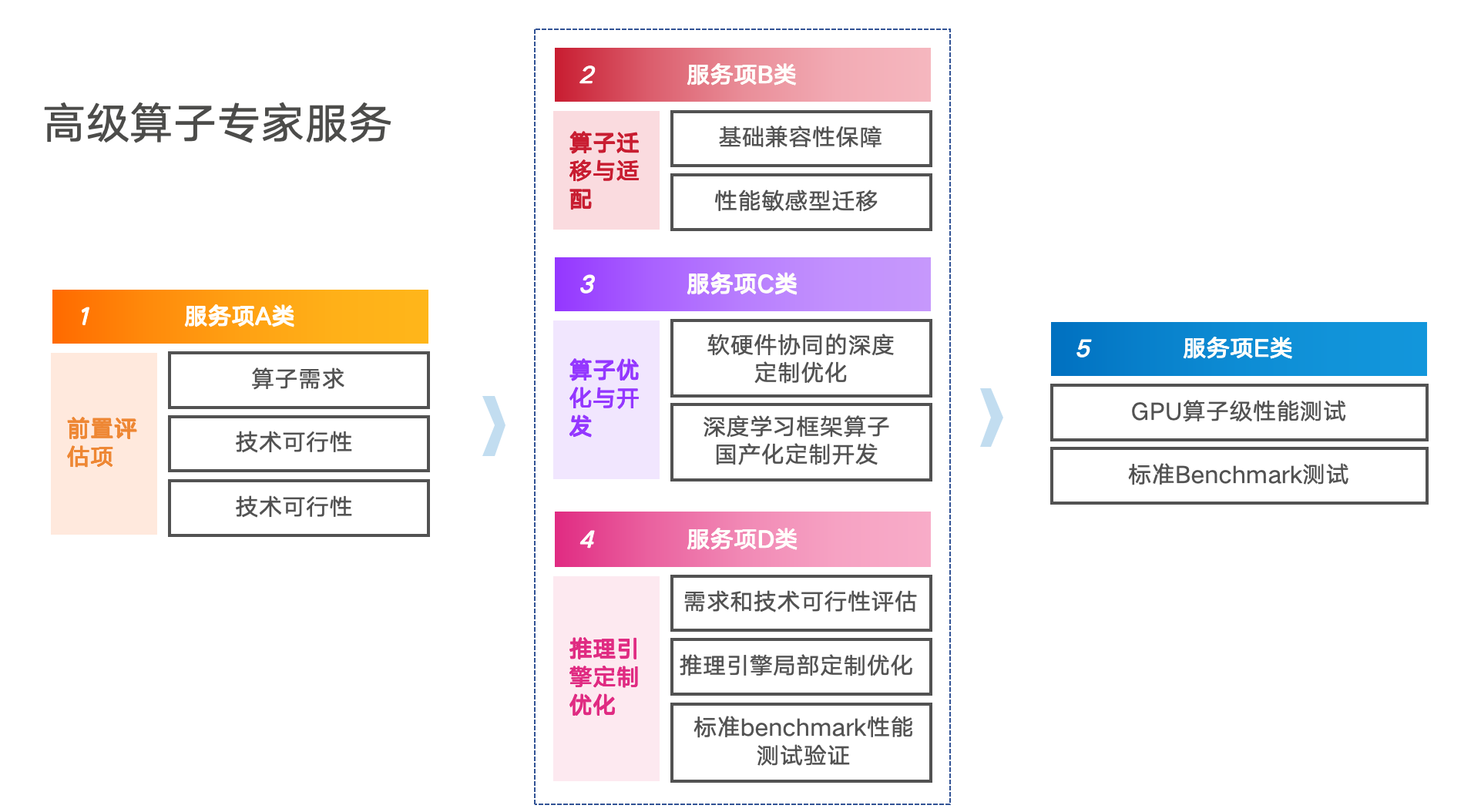
关于AI自动做算子优化:这波Google Gemini 3.0大模型的登顶,意味着第一个非英伟达芯片支撑的大模型杀出来了。Google提出了很多爆炸性的思路,同样可以用在中国国产卡生态。夏天看了Google的一篇用DeepSeek自动探索底层算子代码优化的论文。TPU驱动层算子优化(对位CUDA和算法框架)不只是活人在做,而是尝试AI做。这意味着DeepSeek震惊世界的工作(在英伟达体系底层深度优化,节省超过十倍算力)可以由AI在国产卡生态里再做一遍,不用非得组建上百人的、年薪十亿的天才团队。离AI在无人干预下,基于国产芯片,完全自主从头开发一个大模型,还有多少个月?