张艺谋75岁依然不停止工作,保持每年1~2部电影的稳定节奏。到目前为止已发布超过50部各种作品,包括2次奥运会开幕式。去年他还发布了一部竖屏手机电影作品。这种旺盛持久的创造力令人惊叹。
咱们来观察一下,我这一代产品经理,有多少人75岁还在发布自己的新版软件?查理芒格投资的DJC,美国法律软件市场第一位的toB软件供应商,其董事长、总经理全都75岁以上,持续专注干了40年。
张艺谋75岁依然不停止工作,保持每年1~2部电影的稳定节奏。到目前为止已发布超过50部各种作品,包括2次奥运会开幕式。去年他还发布了一部竖屏手机电影作品。这种旺盛持久的创造力令人惊叹。
咱们来观察一下,我这一代产品经理,有多少人75岁还在发布自己的新版软件?查理芒格投资的DJC,美国法律软件市场第一位的toB软件供应商,其董事长、总经理全都75岁以上,持续专注干了40年。
不重视工程技术,只会利用人口规模和恶性内卷。天天琢磨囚徒困境下的逢迎揣测,反复上演甄嬛传。这是儒家思想最糟粕的地方。日本有世界级的银矿,澳大利亚有世界级的铁矿,西伯利亚有世界级的油汽矿。但凡汉族几千年里稍微有一点进取心,这些家门口的资源也不会落入古希腊时代就开始努力航海的白人殖民者之手。
朋友圈各种年度总结。关于2023,只想发这个孩子的照片。希望大家能像他一样,向着目标自由奔跑。



去年写过卦象,挺好玩。今年再写写,2024雷火丰,是要求行动力的一年。简明高效,赏罚分明,谋定而后动,即能逢凶化吉。
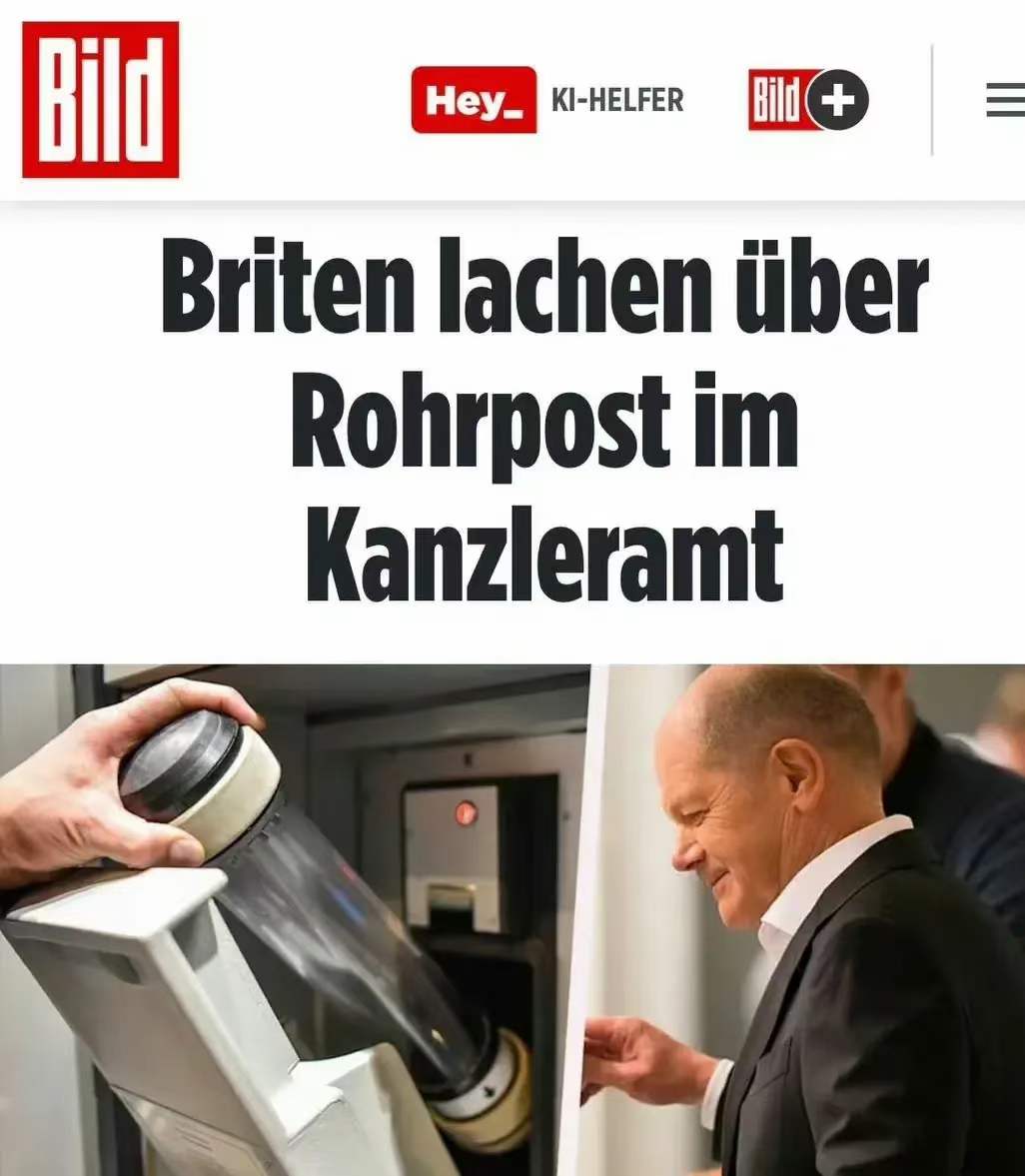
气动邮件系统应该是工程师们最想拥有的玩具之一吧。在我心目里仅次于齿轮差分机。最后一张的新闻在说,德国总理坚持在政府中保留气动邮件系统。公开理由是为防止俄国黑客,实际原因是因为他们的手机和邮件系统都被美国情报机构监控。


新年好!
很多朋友找我要这次产品发布会视频。从这个链接进去,注册账号填写信息就可以了。
SimbaOS的API/SDK/Schema目前仅供DataSimba R4及以上版本的老客户限期试用。
DataSimba不是万能的,一般限于大规模OLAP场景。你可能首先需要靠谱的业务分析。我们提供收费的PoC(先期体验)、数据战略咨询、引擎压力测试和选型、数据迁移等服务。
联系方式如下(工作日09:00 – 18:00):
电话:400-080-0326
微信号:Startdt001
邮箱:business@startdt.com
BTW:2024年,把产品回款再增加一倍。市场方面拉开和竞争对手的距离。
Linux的OS Kernel昨天刚发布了6.6.6版。作为追更25年的老粉丝,庆祝。还记得1999年我在大学里面办讲座,开设“joyfire linux 源码阅读笔记”的网站,介绍Linux这种奇怪的东西,很多人听不懂。
专业深度思考得到的反共识才值钱。平庸的二流脑袋,找不到世界的版本漏洞,总想抄未必高明的作业,追逐当下热炒的buzz word标签。这次经济危机,世界正在帮我们消灭不独立思考、抄袭纸糊的copy cat。
日本停滞三十年,除金融崩溃以外的重要原因是,1990年美国突然把原本为核战争通讯而研发的互联网技术,开放给民间商用接入。日本业界停留在1980年代汽车、消费电子、人工智能的研发上,没及时转向互联网方向。1996年后那一波互联网大潮,日本本土的创业团队完全没赶上。(但日本VC软银投资了开启互联网大潮的美国Yahoo)。
最近美资VC从中国撤退,本土资本能否“国产替代”,支撑创业者创新试错,这是关顾国运的大事。看一下国内一级二级市场这两年热炒的那些浮躁的题目,还差很远。
回来说我们自己,前两天的发布会,关于SimbaOS的思路收到了不少反馈。感觉在业内引发的动静比每年Q4的常规发布会要大一些。但未必都认同。没事,反而希望全行业别那么快和我一致,看不懂、看不上的时间久一点。
最近发现,Postgres创始人、数据库领域“祖师爷”,图灵奖获得者Michael Stonebraker与Apache Spark 作者 Matei Zaharia发表了一篇名为DBOS: A Proposal for a Data-Centric Operating System的论文。很激动。
好久没写,被人催更。那就立一个目标:2024年写12篇BLOG。另外,12月份我会写点东西总结今年。也未必都写严肃的工作和行业,也可以转载朋友的好文章、贴点读书笔记、发点旅行照片什么的。
前两天和别人聊天,自夸,吹的牛能落地。
例子1:刚到Simba团队时找大家One on one:“半年后会发生什么,一年后、两年后会遇到什么困难……所以roadmap先做啥后做啥……到时候再回忆现在说的话”。前两天在部门大会上讲,尽管遇到了大环境的变数很多事拖延了,但我们日拱一卒拿下了当初计划的山头。(老板真懂且真心想做,公司上下一心,各种资源倾斜到Simba,这非常难得)
例子2:邀请z博士来,给她认真写过一篇小作文:怎样才能平稳落地,接下来一两年的主攻什么,放弃什么。现在看来我没忽悠她,虽然遇到很多困难,基本上在按照当时的规划一步步实现。(当然,z博士强大的内心和超强的执行力是关键)
我晚熟,三十多岁才明白一些道理。比如要专注。比如天助自助者。
熟悉我Blog的人都知道,我习惯每年年初想清楚几个目标,其余皆可放弃。一旦专注起来,环境就只是跑道地形,不影响目标距离。队友和对手未必完美,也不重要,别阻碍我去终点就好(反过来,谁真挡路就动手铲平为止)。这十几年,有时定了4个目标居然都能达到,有时只定1个目标还不满意,运气弄人,但念念不忘必有回响。
刘青云在颁奖仪式上讲的挺有趣:“如果大家真的有梦想,又努力又长命,梦想最终会奇怪地又带点遗憾地实现的。没关系,世事岂能尽如人意。”
23andMe遭黑客攻击,700万用户DNA数据泄露,包括马斯克、扎克伯格等众多名人的信息。马斯克的基因父系类型是东亚高频的O2(O2b1-F1150)。这就和马斯克太爷是私生子的家族历史印证。他的祖源与目前江苏宜兴宗氏、浙江宁波殷氏有共同父系祖先。
其实很多事实很残酷,比如美国黑人的DNA数据,99%都是欧洲父系。我本来不想举中国的例子,山东孔家接近中亚/高加索人的父系基因哪里来的?而且不止一次基因突变,一次在南北朝,一次在元朝。这其实不只是种族问题,还是阶级问题。此前看过一篇社会遗传学的论文,通过对比族谱和基因,300年前的中国男性95%已经绝后。只有地主阶级的父系基因才能遗传至今。
程序员,用代码在CPU、GPU和内存里写诗,用数据喂养终将超越人类的模型,用网络连接急切、孤独和愤怒的角落,用搜索和推荐驱动消费和时尚,用视频和美颜重塑社交和群体。 程序员,恰如此前时代的机械和电器工程师,用技术改变了全世界,同时自己也被时代席卷。
希望每个程序员保留初衷,依然能品尝到最初一段hello world代码跑通时的内心乐趣。我们的使命是造出一个AI替代程序员自己,但是在那之前,让我们先造出一个AI来把隔壁产品经理都替代掉。
Snowflake和Databricks的CEO又吵架了。原因是Instacart上市前披露数字,2020年向雪花付了1300万美元,2021年2800万,2022年5100万。结果到2023年变成1500万了,其他很大一块数据业务被切到砖块去了。雪花和砖块这两家动不动就撕,全行业吃瓜。
顺便一提,Snowflake买Neeva,更多是用ChatGPT开发数据分析、搜索的应用。而Databricks买MosaicML,是做DB4AI,让客户可以在他的数据云平台上训练、部署、运维自己的私有大模型。